과제3.Image Captioning with Vanilla RNNs
Image Captioning with Vanilla RNNs 코드 구현
1. Introduce
이번 챕터에서는 이미지 캡션에 대해 공부할 예정이다.
캡션을 사용하기 위해서는 자연어 처리에 오래된 친구인 RNN부터 transformer, lstm 구현할 예정이다.
이번시간에는 RNN 기반인 이미지 캡션을 구현할 것이다.
캡션을 사용하기 위해서는 자연어 처리에 오래된 친구인 RNN부터 transformer, lstm 구현할 예정이다.
이번시간에는 RNN 기반인 이미지 캡션을 구현할 것이다.

위에서 그럼을 보듯이 'h'라는 변수가 존재합니다.
'h' 변수의 역할은 이전에 출력된 결과 값을 시간적으로 저장하는 것이며, 이를 통해 재귀적으로 이후 네트워크와 연동됩니다.
이러한 논리는 자연어 처리에 매우 중요하며, RNN은 기본적인 자연어 처리 네트워크로 사용됩니다.
'h' 변수의 역할은 이전에 출력된 결과 값을 시간적으로 저장하는 것이며, 이를 통해 재귀적으로 이후 네트워크와 연동됩니다.
이러한 논리는 자연어 처리에 매우 중요하며, RNN은 기본적인 자연어 처리 네트워크로 사용됩니다.

2. Train
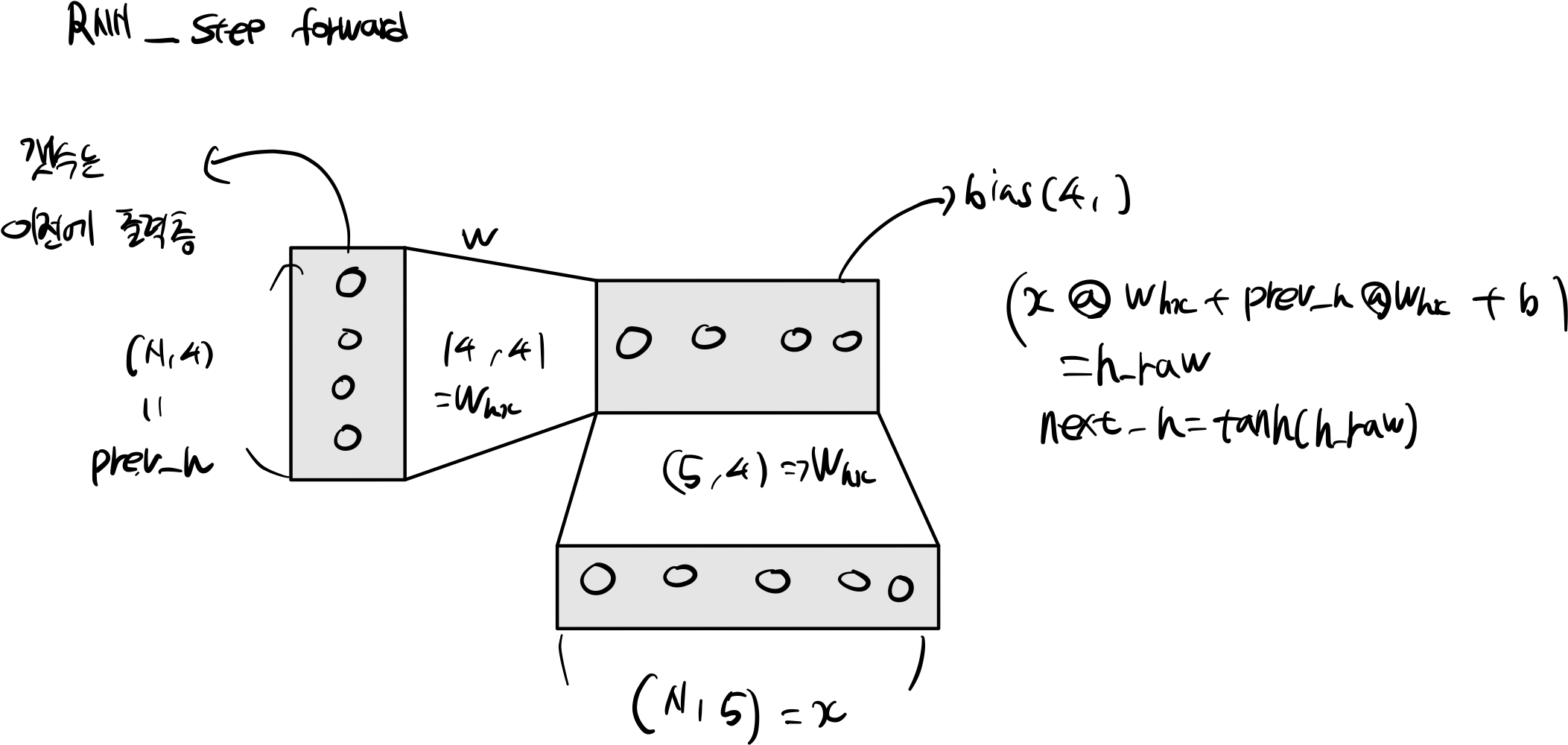
2.1 Rnn Step Forward
def rnn_step_forward(x, prev_h, Wx, Wh, b):
h_raw = x.dot(Wx) + prev_h.dot(Wh) + b
next_h = np.tanh(h_raw)
cache = (next_h, x, prev_h, Wx, Wh)
return next_h, cache
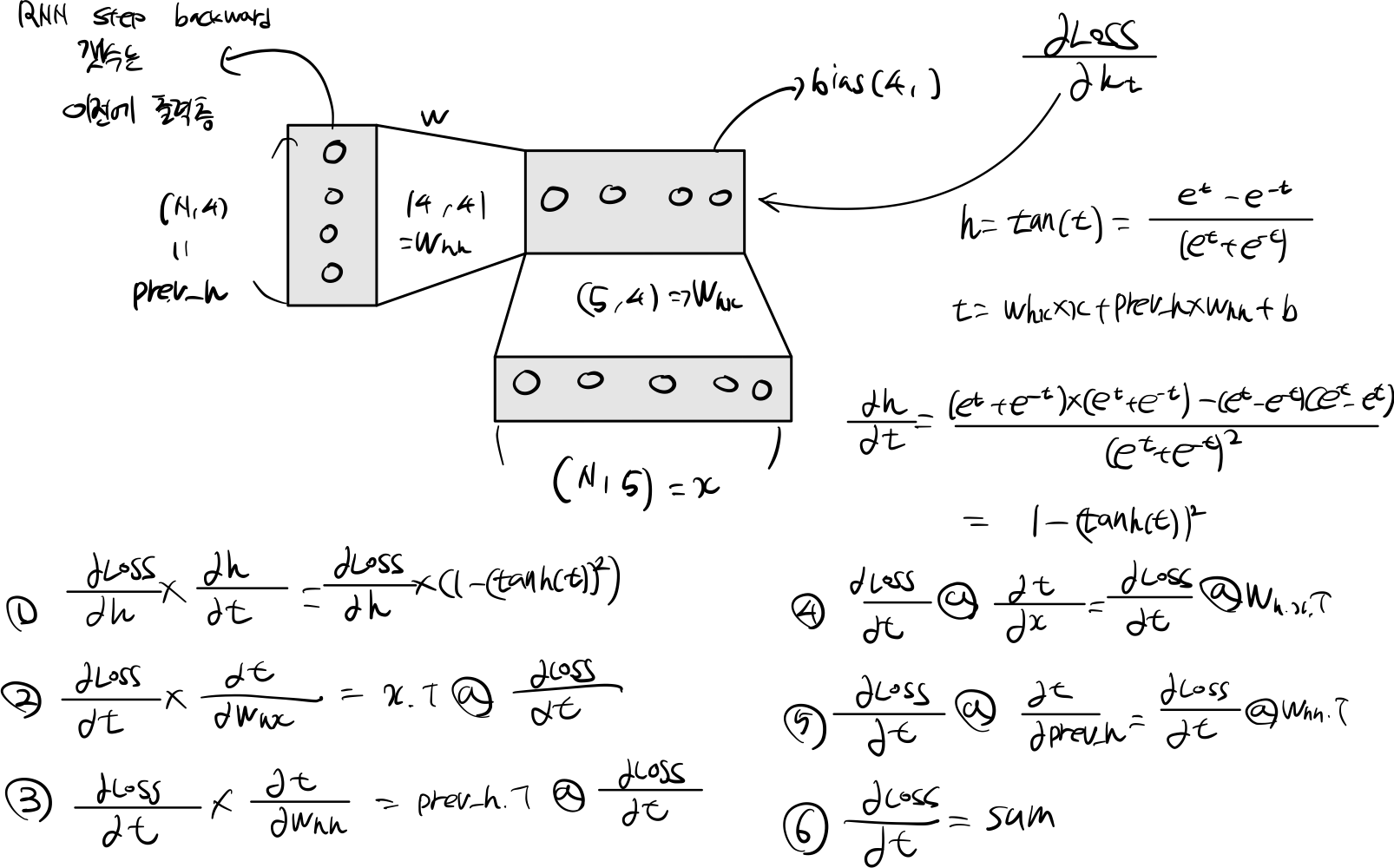
2.2 Rnn Step Backward
def rnn_step_backward(dnext_h, cache):
next_h, x, prev_h, Wx, Wh = cache
dout = (1- np.square(next_h)) * dnext_h
dWx = x.T @ dout
dWh = prev_h.T @ dout
dprev_h = dout @ Wh.T
dx = dout @ Wx.T
db = np.sum(dout, axis=0)
return dx, dprev_h, dWx, dWh, db

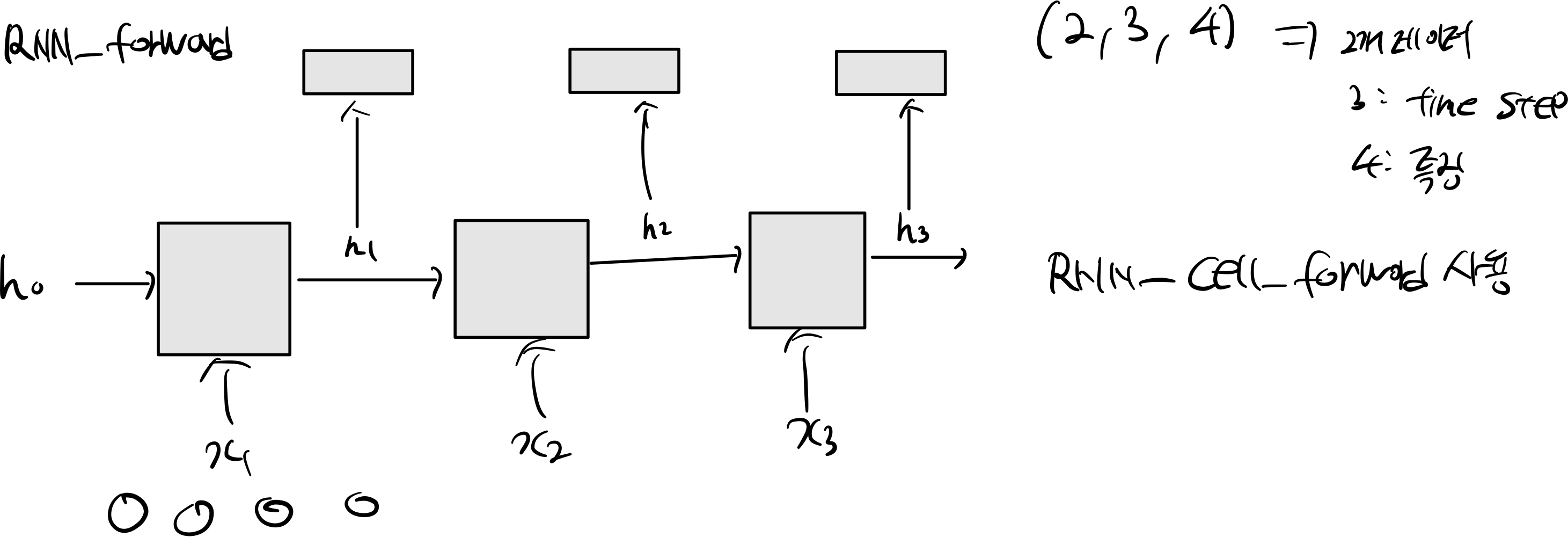
2.3 RNN Forward
def rnn_forward(x, h0, Wx, Wh, b):
h, cache = None, None
cache = []
h = [h0]
time_step = x.shape[1]
h_stack = np.zeros((x.shape[0], time_step, b.shape[0]))
for t in range(time_step):
next_h, new_cache = rnn_step_forward(x[:, t], h[t], Wx, Wh, b)
h_stack[:, t] = next_h
h.append(next_h)
cache.append(new_cache)
h = np.stack(h[1:], axis=1)
return h, cache
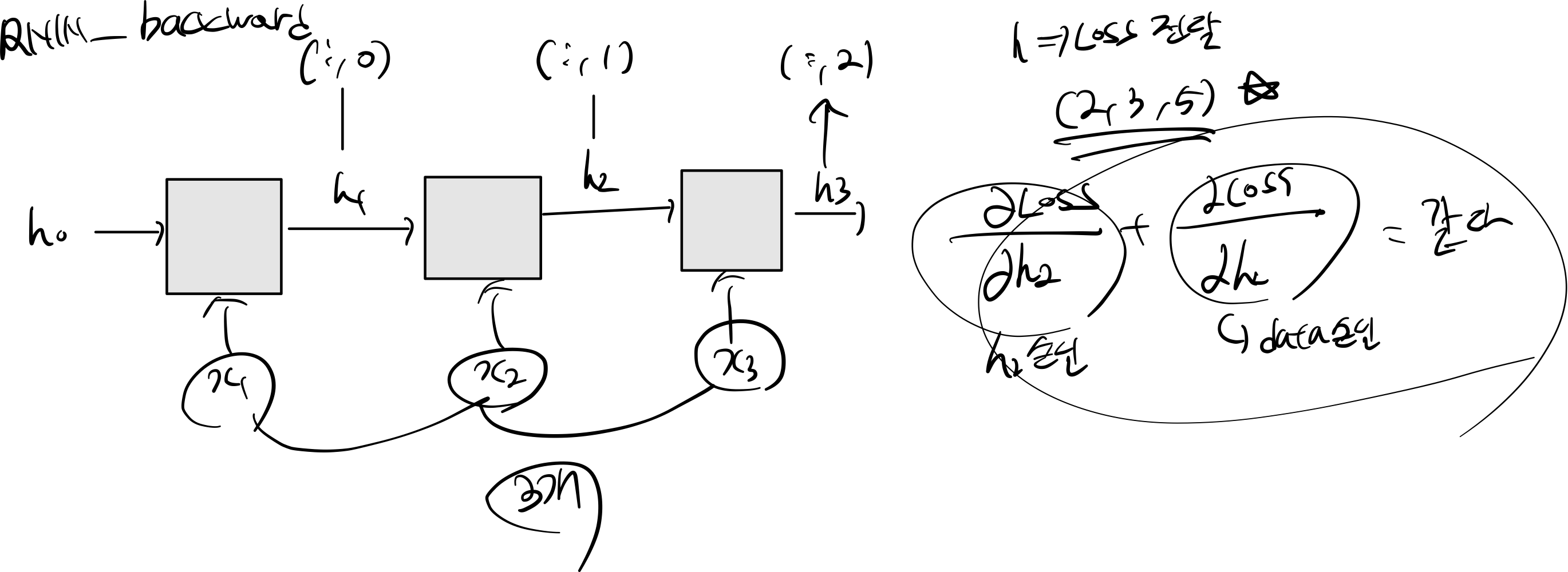
2.4 RNN Backward
def rnn_backward(dh, cache):
(N, T, H), (D, _) = dh.shape, cache[0][3].shape
dx = np.empty((N, T, D))
dh0 = np.zeros((N, H))
dWx = np.zeros((D, H))
dWh = np.zeros((H, H))
db = np.zeros(H)
for t in range(T-1, -1, -1):
dx_t, dh0, dWx_t, dWh_t, db_t = rnn_step_backward(dh[:, t] + dh0, cache[t])
dx[:, t] = dx_t
dWx += dWx_t
dWh += dWh_t
db += db_t
return dx, dh0, dWx, dWh, db
2.5 Word Embedding forward
def word_embedding_forward(x, W):
out = W[x, :]
cache = x, W
return out, cache
2.6 Word Embedding backward
def word_embedding_backward(dout, cache):
x, W = cache
dW = np.zeros_like(W)
# Ref: https://docs.scipy.org/doc/numpy-1.14.0/reference/generated/numpy.ufunc.at.html
np.add.at(dW, x, dout)
return dW
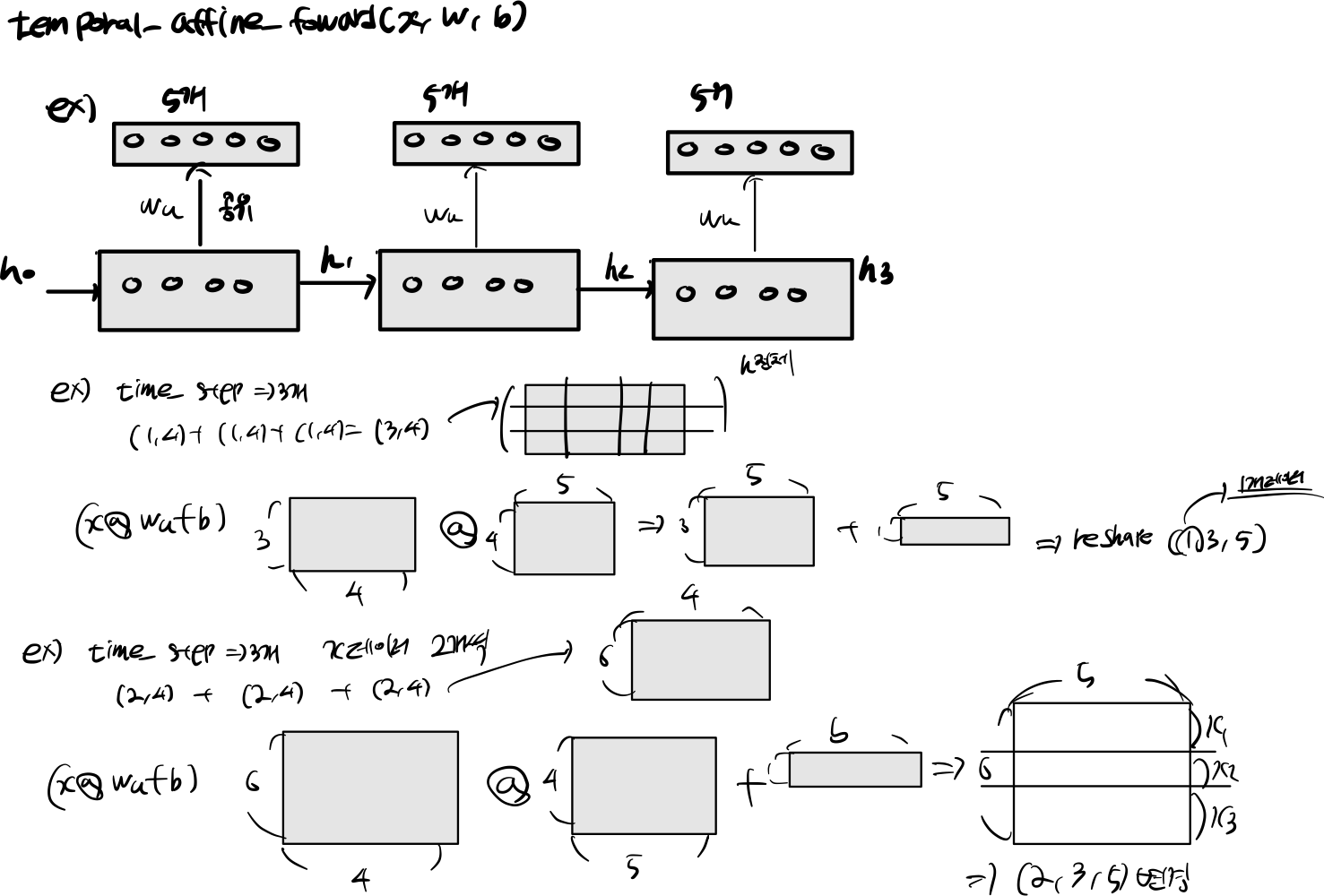
2.7 temporal_affine_forward
def temporal_affine_forward(x, w, b):
N, T, D = x.shape
M = b.shape[0]
out = x.reshape(N * T, D).dot(w).reshape(N, T, M) + b
cache = x, w, b, out
return out, cache
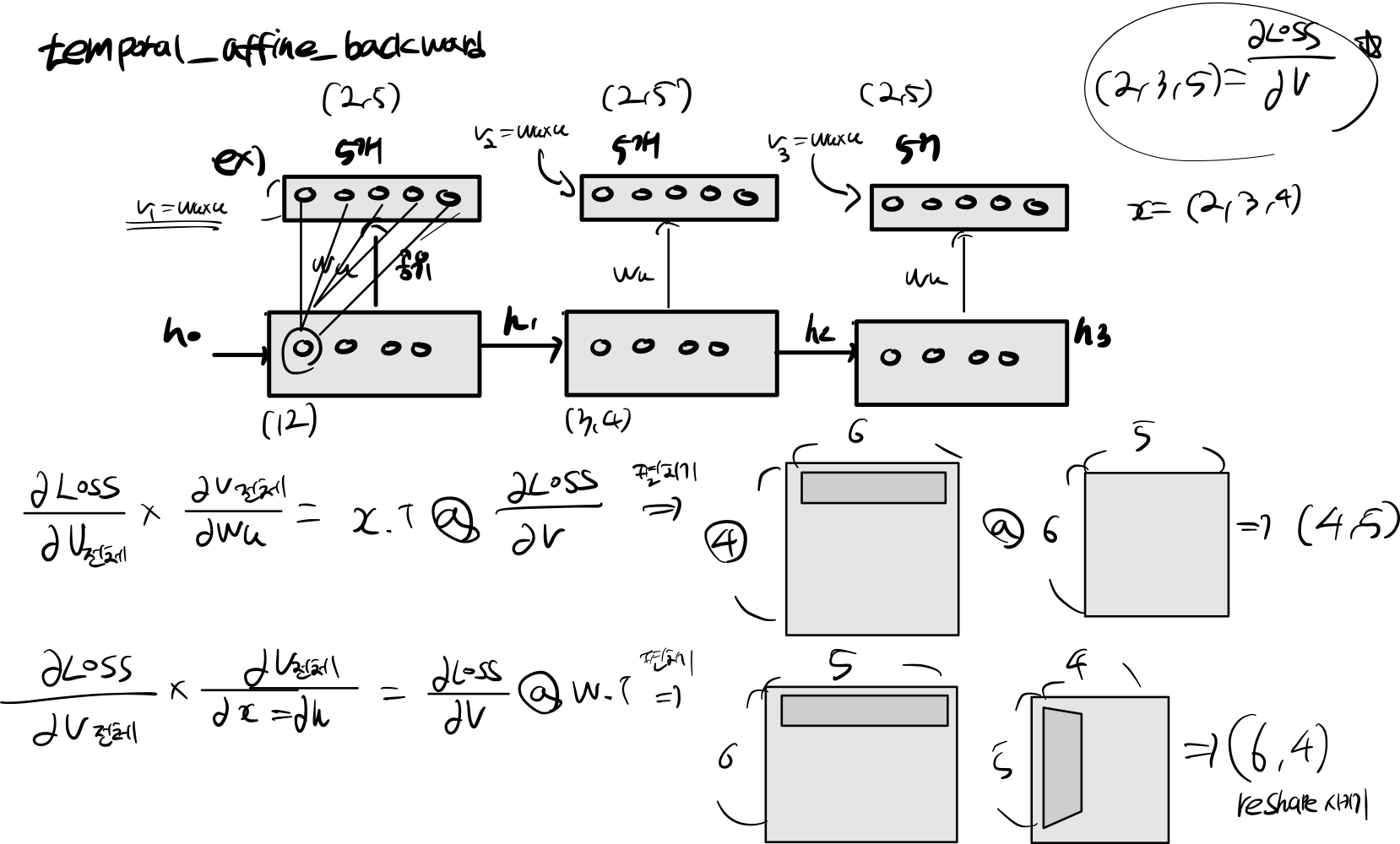
2.8 temporal_affine_backward
def temporal_affine_backward(dout, cache):
x, w, b, out = cache
N, T, D = x.shape
M = b.shape[0]
dx = dout.reshape(N * T, M).dot(w.T).reshape(N, T, D)
dw = (x.reshape(N * T, D).T @ dout.reshape(N * T, M))
db = dout.sum(axis=(0, 1))
return dx, dw, db
2.9 Solver train
#Cnn -> FC 변경
cnn_fc, fn_cache = affine_forward(features, W_proj, b_proj)
embedded_captions, cache_word_embedding = word_embedding_forward(captions_in, W_embed)
if self.cell_type == 'rnn':
rnn_outputs, cache_rnn = rnn_forward(embedded_captions, cnn_fc, Wx, Wh, b)
scores, cache_scores = temporal_affine_forward(rnn_outputs, W_vocab, b_vocab)
loss, dsoftmax = temporal_softmax_loss(scores, captions_out, mask)
dscores, dW_vocab, db_vocab = temporal_affine_backward(dsoftmax, cache_scores)
grads['W_vocab'], grads['b_vocab'] = dW_vocab, db_vocab
if self.cell_type == 'rnn':
dx, dh0, dWx, dWh, db = rnn_backward(dscores, cache_rnn)
grads['b'], grads['Wh'], grads['Wx'] = db, dWh, dWx
dW_embed = word_embedding_backward(dx, cache_word_embedding)
grads['W_embed'] = dW_embed
dx_initial, dW_proj, db_proj = affine_backward(dh0, fn_cache)
grads['W_proj'], grads['b_proj'] = dW_proj, db_proj

Additional references
- https://cs231n.github.io